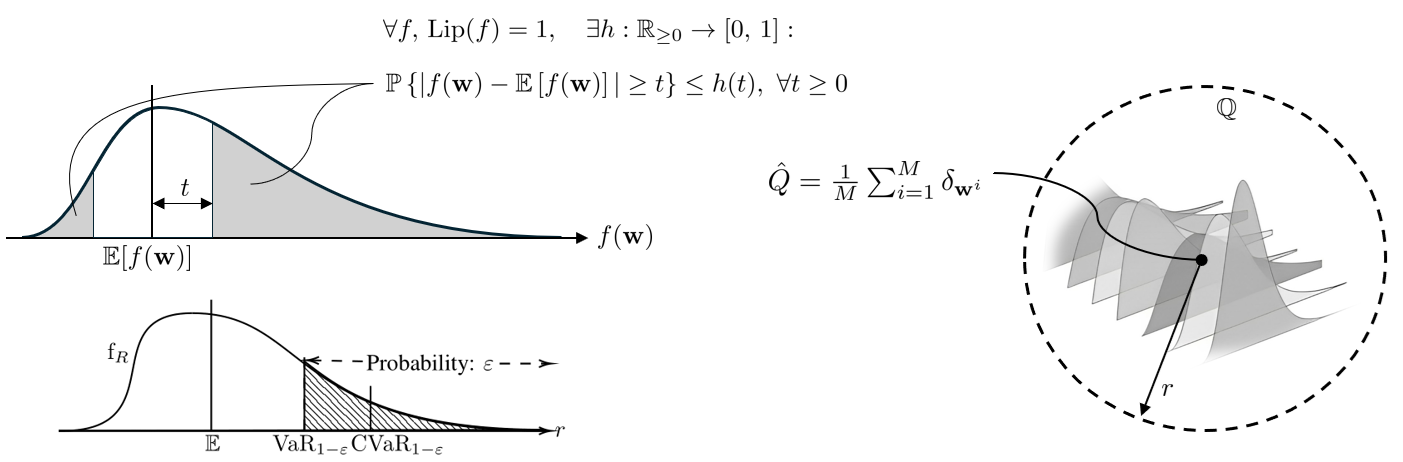Stochastic Systems under Signal Temporal Logic Tasks
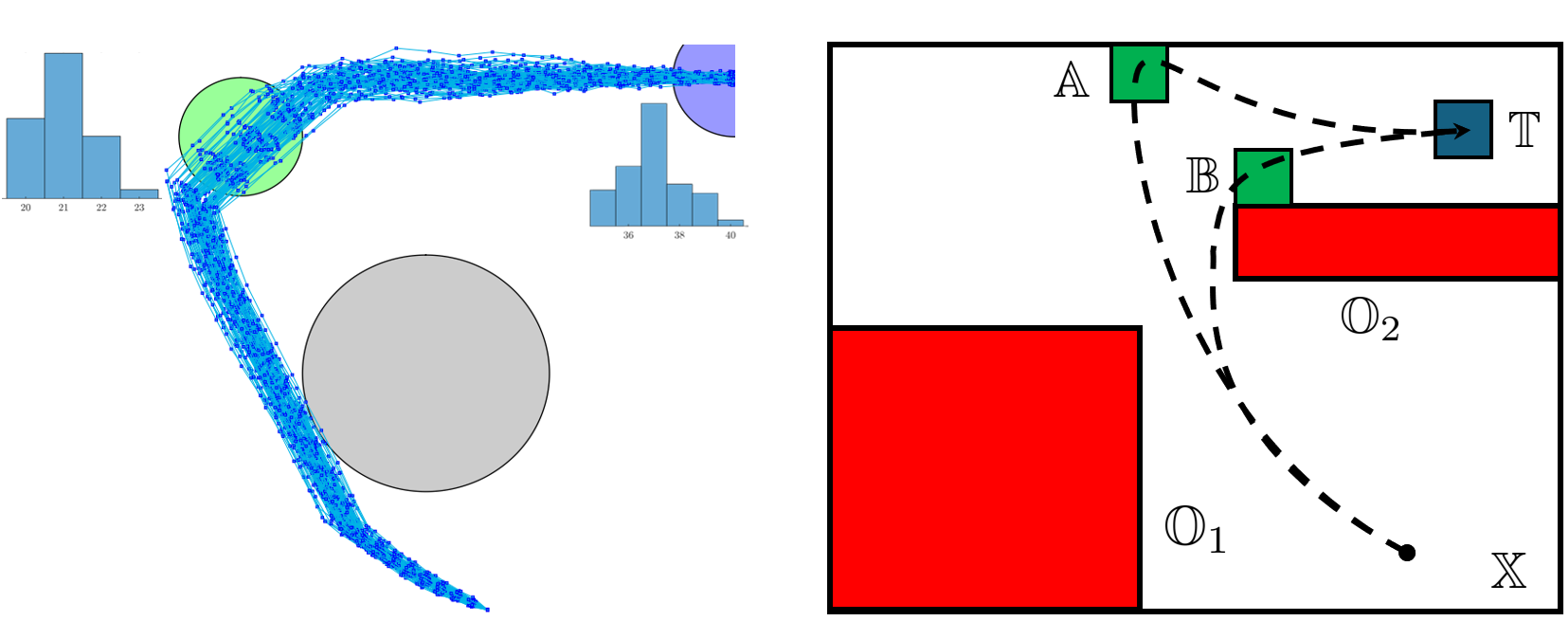
Signal Temporal Logic (STL) provides a powerful framework for specifying complex high-level spatio-temporal tasks in dynamical systems. This research focuses on offering probabilistic guarantees that stochastic dynamics will meet a given STL task. Figure 1-right displays an STL task, while the left side shows various trajectories and a histogram of reaching times for satisfying an STL formula with deadlines.
Fig 1: Left: Trajectories of a stochastic system under STL task. Right: An example of an STL task: The robot must reach a target set within a specified time, navigate through one of two designated sets, and avoid other specified sets.
Barrier functions provide Lyapunov-like assurances for system behavior, aiding in safety verification. Specifically, Control Barrier Functions (CBFs) are valuable for developing control strategies in safety-critical systems. In the context of stochastic systems, CBFs are constructed using the concept of supermartingales. One approach is to explore time-varying CBFs within a robust optimization framework to establish a lower bound on the probability of satisfying a given STL specification with a specified robustness level.
Another approach involves directly solving a chance-constrained program (CCP) to provide a lower bound on STL satisfaction. Techniques such as concentration of measure theory and conditional value at risk can be employed to transform the CCP into a stochastic programming problem with expectation constraints. Subsequently, a data-driven Wasserstein distributionally robust program can be used to offer guarantees based on a finite set of disturbance realizations. See Figure 2.
Fig 2: STL specifications can be guaranteed using a chance-constrained program (CCP). This CCP can be solved with techniques such as concentration of measure theory and conditional value at risk, combined with a distributionally robust approach.
MPC-based Reinforcement learning
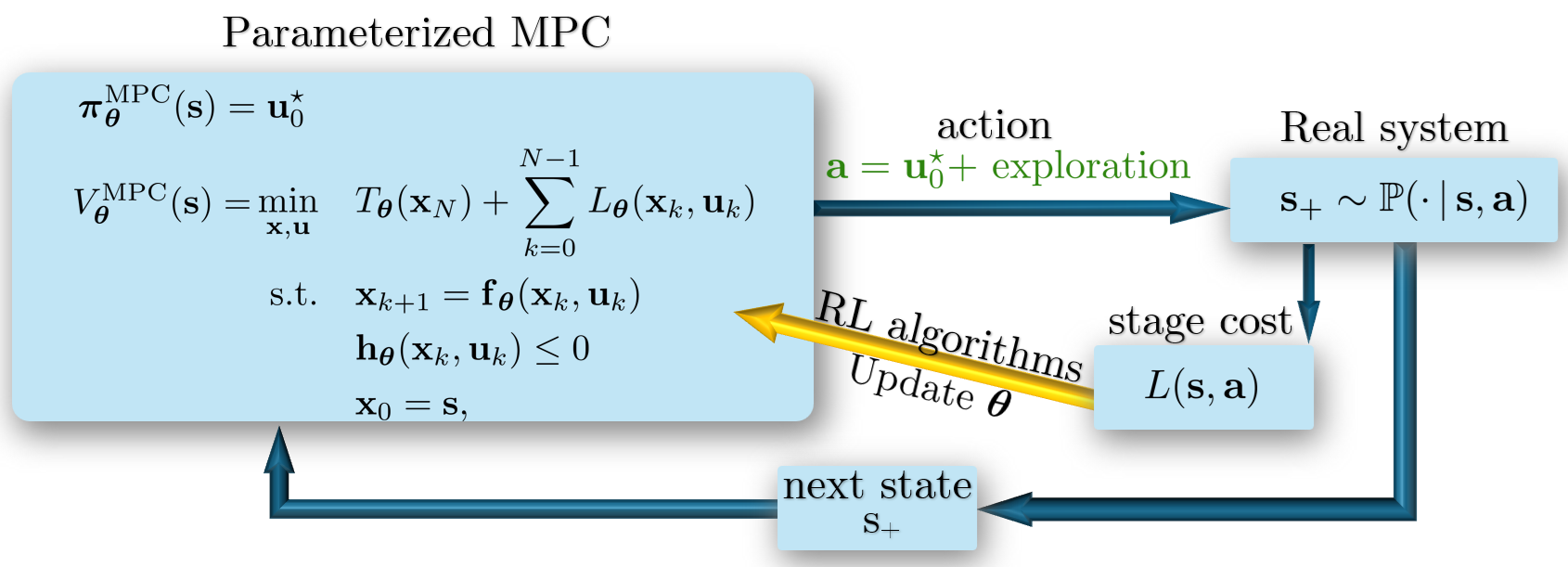
This research plays around the idea of optimizing the closed-loop performance of an MPC-based policy by tuning the entire MPC scheme (model, cost, and constraints). Reinforcement Learning (RL) is then proposed to optimize the closed-loop performance of the MPC scheme using data from the real system. This approach is arguably unique in the field of learning-based MPC, as it does not focus purely on improving the MPC model accuracy but rather on improving the MPC closed-loop performance. Moreover, it ties the learning directly to the closed-loop performance of the resulting MPC policy.
From an RL perspective, this approach can be seen as a doorway to developing safe, stable, and explainable RL methods, which is not possible in classical Deep RL, where Deep Neural Networks (DNNs) are employed to generate the policies. In the RL context, using MPC as an approximation of the optimal policy can be construed as a way of introducing a strong structure in RL, as opposed to the more classical way of approximating the optimal policy via DNNs. A different perspective is to see RL as a rich toolbox for adjusting the MPC scheme from data to improve its closed-loop performance. Figure 3 summarizes the idea.
Fig 3: Schematic of MPC-based RL algorithm.
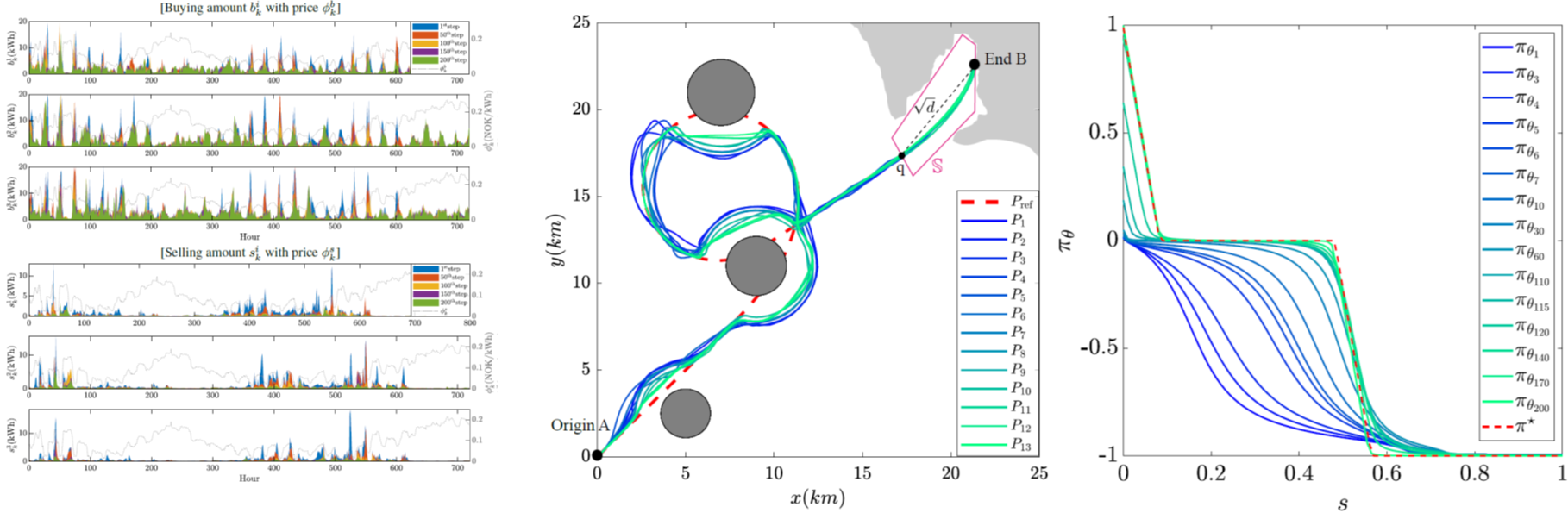
The research has garnered both theoretical interest, such as showing the optimality equivalency, and practical interest as illustrated in Figure 4.
Fig 4: Application area of MPC-based RL. From left to right: multi-agent smart-grid system, autonomous surface vehicle, and battery storage.